FCPO: Federated Continual Policy Optimization for Real-Time High-Throughput Edge Video Analytics
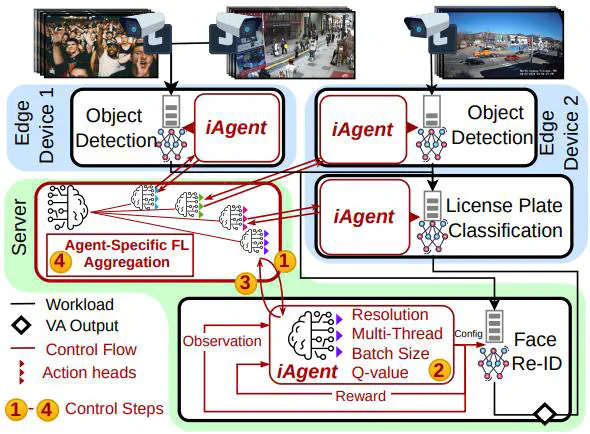 FCPO’s learning architecture
FCPO’s learning architectureAbstract
The growing complexity of Edge Video Analytics (EVA) facilitates new kind of intelligent applications, but creates challenges in real-time inference serving systems. State-of-the-art (SOTA) scheduling systems optimize global workload distributions for heterogeneous devices but often suffer from extended scheduling cycles, leading to sub-optimal processing in rapidly changing Edge environments. Local Reinforcement Learning (RL) enables quick adjustments between cycles but faces scalability, knowledge integration, and adaptability issues. Thus, we propose FCPO, which combines Continual RL (CRL) with Federated RL (FRL) to address these challenges. This integration dynamically adjusts inference batch sizes, input resolutions, and multi-threading during pre- and post-processing. CRL allows agents to learn from changing Markov Decision Processes, capturing dynamic environmental variations, while FRL improves generalization and convergence speed by integrating experiences across inference models. FCPO combines these via an agent-specific aggregation scheme and a diversity-aware experience buffer. Experiments on a real-world EVA testbed showed over 5 times improvement in effective throughput, 60% reduced latency, and 20% faster convergence with up to 10 times less memory consumption compared to SOTA RL-based approaches.
Type
Publication
arXiv